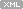이런 식으로 numpy array에서 torch tensor를 만들 수도 있다. 출력 결과는 같다.
x_ones = torch.ones_like(x_data) # x_data와 같은 모양이지만, 모든 값이 1인 텐서
x_rand = torch.rand_like(x_data, dtype=torch.float) # x_data와 같은 모양이지만, 무작위 값(0~1)을 가지는 Float형 텐서
같은 모양의 one tensor 또는 random 값을 갖는 tensor도 만들 수 있다. 다 필요가 있는 것이겠지.. ㅎㅎ
텐서의 주요 속성
텐서를 생성한 후에는 그 텐서의 크기(모양)나 자료형을 확인하는 것이 중요
모양(shape)
자료형(data type)
텐서가 저장된 장치(device)
# 텐서의 속성 확인 (Checking the tensor's attributes)
print(f"텐서의 모양 (Shape): {x_data.shape}")
print(f"텐서의 자료형 (Data Type): {x_data.dtype}")
print(f"텐서가 저장된 장치 (Device): {x_data.device}") # 현재는 CPU일 것입니다.
numpy array에서처럼 shape을 잘 보는 게 좋을텐데 shape 정보를 불러오는 형태는 같네. 자료형은 속성명을 dtype으로. 그리고 사실 device는 numpy에서는 못보던 속성이다. 이 속성은 잘 기억해둬야겠다. 그리고 출력 결과를 보니 다 torch에서 정의한 정보들(torch.Size([]), torch.int64 등)이라고 나오네.
텐서 연산 및 GPU 사용
Pytorch를 사용하는 핵심 이유 중 하나가 GPU를 활용하여 연산 속도를 극대화할 수 있기 때문이라고.
그래서 그런지 연산과 관련해서 그냥 흔히 쓰는 연산자 말고 torch에서 제공하는 함수를 쓰는 게 좋을 것 같다.
# 행렬 곱셈 (Matrix Multiplication - Dot product)
# tensor는 (2, 2) 모양, y는 (2, 2) 모양입니다.
z_matmul_1 = tensor.matmul(y)
z_matmul_2 = tensor @ y # 파이썬에서 행렬 곱셈을 위한 연산자 (Operator for matrix multiplication)
print(f"행렬 곱셈 결과 (z_matmul_1):\n{z_matmul_1}")
print(f"행렬 곱셈 결과 (z_matmul_2):\n{z_matmul_2}")
행렬 곱셈(내적)도 ㅇㅋ
이제 GPU를 써보자.
# GPU (CUDA) 사용 가능 여부 확인 (Check if GPU (CUDA) is available)
if torch.cuda.is_available():
device = torch.device("cuda")
print("GPU (CUDA)를 사용할 수 있습니다.")
else:
device = torch.device("cpu")
print("GPU를 사용할 수 없으므로 CPU를 사용합니다.")
아직은 Google Colab을 쓰고 있는데, 거기도 runtime 유형을 GPU로 선택하면 GPU를 사용가능하다고 나온다. 나중에 내 데스크톱에서도 하게 된다면 꼭 확인해볼 코드.
이제 torch tensor를 GPU로 이동해보자. (아까는 device 속성이 CPU였음)
# CPU에 있는 텐서 (Tensor currently on CPU)
x_data = torch.tensor([[1.0, 2.0], [3.0, 4.0]]) # 주의: GPU로 옮기려면 보통 float 타입 사용
# 텐서를 설정된 장치(device)로 이동 (Move the tensor to the configured device)
x_data_on_device = x_data.to(device)
print(f"원래 텐서의 장치: {x_data.device}")
print(f"이동된 텐서의 장치: {x_data_on_device.device}")
# GPU 텐서에 대한 연산도 동일하게 수행됩니다. (Operations on GPU tensors are performed the same way.)
z_gpu = x_data_on_device @ x_data_on_device
print(f"GPU에서 수행된 행렬 곱셈 결과:\n{z_gpu}")
뭐 잘 된 거겠지. ㅎㅎ 이정도 계산으로 차이를 체감할 수는 없을 테고. 특별한 건, torch tensor를 출력할 때 device 속성이 같이 출력된다는 점. CPU로 할 때는 안 보였었는데. 여튼 이렇게 다 확인해보니 마음이 편하다.
그나저나 GPU를 쓰고 싶으면 이렇게 다 모든 torch tensor에 대해 device 속성을 바꿔주고 해야 하는 건가..? 함수로 퉁치는 건 안되나... 뭐 일단 그건 나중에 더 알게 되겠지.
자동 미분 및 Requires Grad 이해하기
Keras로 인공지능 모델을 만들 때는 이런 것까지 공부하지는 않았던 것 같은데,
커스터마이징을 할 때는 필요할 수도 있다고 해서 일단 이 내용도 공부는 해본다.
어차피 내용이 많아보이지는 않고, 이것도 따지고 보면 진짜 미분 계산을 내가 해야 하는 게 아니고 그냥 연산 과정을 추적하게 하는 걸 허용하겠다 말겠다 정도의 수준이니 살펴는 보자.
torch tensor가 생성될 때 requires_grad=True로 설정되면 이 텐서에 대해 수행되는 모든 연산을 추적하기 시작하고, 이는 미분 값을 계산하는 데 필요한 정보를 저장함.
import torch
# requires_grad=True로 설정된 텐서 생성
x = torch.tensor(3.0, requires_grad=True)
y = torch.tensor(4.0, requires_grad=True)
# requires_grad가 False인 텐서 (기본값)
a = torch.tensor(5.0)
print(f"x의 requires_grad: {x.requires_grad}")
print(f"a의 requires_grad: {a.requires_grad}")
순전파(Forward Pass)는 입력 데이터가 모델(수식)을 통과하며 출력을 만들어내는 과정이며, 이 과정에서 Autograd가 연산 그래프르 구축한다...는데 Autograd가 뭔지는 굳이 알지 않아도 될 것 같다. requires_grad를 True로 하고 나중에 grad 속성으로 미분 값을 확인한다는 정도만 알면 될듯.
# 순전파: z = (x^2) + 2y
z = x**2 + 2 * y
print(f"순전파 결과 z: {z}")
# 미분 값 계산: z를 x와 y로 미분
# z.backward()를 호출하면 z가 정의된 연산 그래프를 역순으로 거슬러 올라가며 미분값을 계산합니다.
# 주의: 스칼라 값(하나의 숫자)에 대해서만 .backward()를 직접 호출할 수 있습니다.
z.backward()
# 계산된 미분 값 (Gradient) 확인
# 미분값은 텐서의 .grad 속성에 저장됩니다.
# 1. z를 x로 미분: dz/dx = 2x
# x=3.0 이므로, dz/dx = 2 * 3.0 = 6.0
print(f"x의 미분 값 (dz/dx): {x.grad}")
# 2. z를 y로 미분: dz/dy = 2
# y=4.0 이더라도, dz/dy = 2
print(f"y의 미분 값 (dz/dy): {y.grad}")
이런 식으로 수식에서 해당 x 값에서의 편미분값, 해당 y 값에서의 편미분값을 얻을 수 있다. 신긔신긔