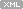본 글은 [1]의 영어 원문에 나온 코드를 이해하기 위해 공부 용으로 정리한 글이다. 원래는 번역도 함께 진행하려고 했는데, 이미 번역본[2]이 있어서 이 글은 코드에 대한 분석만 진행한다.
[1] 원문 https://towardsdatascience.com/gan-by-example-using-keras-on-tensorflow-backend-1a6d515a60d0
[2] 한글 번역 https://brunch.co.kr/@rapaellee/18
전체 코드(약 200줄)
https://github.com/roatienza/Deep-Learning-Experiments/blob/master/Experiments/Tensorflow/GAN/dcgan_mnist.py
*주의: 본문은 아주아주 기초적인 코드 내용 분석까지 시도하기 때문에 기본적인 것들을 이미 아시는 분들은 지루하실 수 있습니다. 딥러닝 자체는 말할 것도 없고 개인적으로 케라스는 몇주 전에 설치했고, 파이썬 자체도 아주 잘 알고 있는 게 아니기 때문에, 파라미터를 하나하나 뜯어내서 공부했습니다.

우선 구조를 보고, 몇가지 생각해보자. 28x28 크기의 gray 이미지를 2D convolution을 이용해 각 단계를 거칠 때마다 해상도는 가로 절반, 세로 절반씩 줄어드는데, 깊이(? 코드 상에서 depth라고 정의해서 쓰고 있다)는 64부터 128, 256, 512로 두배씩 증가하고 있다. 아 그러고 보니 세번째에서 네번째는 해상도는 그대로네. 그리고 마지막에 바로 시그모이드 함수로 확률 값을 얻어낸단다. 왜 이런 구조를 생각해냈을까... 코드를 다 공부해보고 다시 질문해보자. 어쩌면 코드 말고 논문을 봐야 할지도 모르겠다. 그리고 마지막에 4x4x512 차원에서 어떻게 1차원으로 넘어갈 수 있는지 궁금하다. 코드를 보면 알겠지. 다른 CNN 코드를 보면 마지막에 fully connected layer를 쓰는데 그걸 안 쓰는 걸까. 아.. 뒤에 코드를 더 보고 알았다. 4x4x512 차원을 Flatten 함수로 8,192길이의 1차원으로 만든 후에 그걸 8,192 → 1로 만드는 fully connected(? 이것도 이렇게 부르는 게 맞나 모르겠는데 틀린 말도 아닌듯)가 있었다. 그림에 딱히 이걸 표현 안해 놓은듯.
이제 코드를 하나씩 보자. (진짜 한 줄씩 볼 예정임)
참고로 전체 코드(약 200줄)는 아래 링크에서 볼 수 있다.
https://github.com/roatienza/Deep-Learning-Experiments/blob/master/Experiments/Tensorflow/GAN/dcgan_mnist.py
지금부터 설명하는 코드는 Discriminator model을 만들어 주는 함수의 코드다.
self.D = Sequential()
시작부터 self.D라는 이상한 놈이 나타났다. python에서 self에 대한 것이 궁금하다면 아래 링크 [3]을 참고하기로 하자. 저 self가 어디서부터 왔고. self에 속한 D는 뭘 의미하는지 알아보자.
[3] https://wikidocs.net/1742
일단 이 코드는 discriminator라는 함수 안에 있는 코드로 self는 이 함수를 맴버함수로 가지고 있는 class를 가리키는 것일 것이다. 전체 코드를 확인해보면 이 class는 DCGAN이라는 이름의 클래스이고, 거기에 있는 맴버 변수 D는 DCGAN class에서 discriminator를 가리키는 변수로 정의되어 있다. 그러니깐 DCGAN이라는 class에서 사용할 discriminator model의 이름을 discriminator라는 함수 내에서 사용하기 위해 저렇게 표현되는 것이다.
그럼 이제 self.D가 discriminator model이라는 것을 알았고, Sequential()은 위 그림에서 봤던 구조를 '순서대로' 이어 붙일 것이기 때문에 사용된 코드다. Sequential을 이용해서 모델을 만드는 경우와 Functional한 방법으로 모델을 만드는 경우가 있는데 이는 링크만 남겨두고 나중에 더 공부해봐야겠다.
(https://jovianlin.io/keras-models-sequential-vs-functional/)
*위 링크의 글을 번역하게 되어 추가로 아래에 링크를 남겨놓는다.
(http://leestation.tistory.com/777)
후... 첫줄 이해하는 것부터 이렇게 오래 걸리다니... 물론 200줄의 코드는 짧은 편이지만 이렇게 시간이 걸려서야... ㅋㅋ 그래도 어쩌겠나.. 공부해야지.
depth = 64
다음은 depth. 이건 위 그림을 보면 어떤 의미인지 알 수 있다. 그러나 나는 여전히 의문이다. 왜 64인가?! ㅋㅋ 지금 단계에서 이해하긴 어려울듯. 코드 해석이 다 끝나고 다시 한 번 퇴고하면서 설명을 보완해놔야겠다.
dropout = 0.4
overfitting을 막기 위해 dropout의 비율을 40%로 한다. dropout이 꼭 필요한 건지는 모르겠지만 해보니깐 더 좋더라... 그러니 쓰자. 뭐 이런 건데... 사공이 많으면 배가 산으로 가니깐 사공을 줄이자는 의미인데, 뭐 아주 틀린 말은 아니다.
[4] dropout과 관련된 설명 http://doorbw.tistory.com/147
input_shape = (self.img_rows, self.img_cols, self.channel)
입력 이미지는 DCGAN class에 img_rows와 img_cols에 정의된 대로 28x28의 해상도이고, gray 이미지라서 channel은 1이다. 곧 input의 shape은 (28, 28, 1). list 형태인 [28, 28, 1]이 아니라 tuple 형태다. 그리고 channel이 맨 마지막에 오는데, 찾아보니 별 말 없으면 data_format에 channels_last라는 옵션을 기본으로 사용하는 듯하다.
[5] list와 tuple의 차이 https://blog.naver.com/ijoos/221263485291
self.D.add(Conv2D(depth*1, 5, strides=2, input_shape=input_shape, padding='same', activation=LeakyReLU(alpha=0.2)))
드디어 본격적인 structure 추가가 시작됐다. Conv2D함수로로 만들어지는 2D convolution을 discriminator model에 추가하는 코드다. add 함수는 사실 저렇게 하면 되는 거구나... 알고 넘어가면 되는데, 뒤에 보면 Conv2D를 사용할 때 input_shape을 따로 알려주지 않는다. 즉, 처음 add하는 layer에만 input_shape을 알려주는데, 이게 아마도 자동으로 입출력 shape을 알고 매칭시켜주는 것 같다. Sequential이랑 functional 공부할 때 더 살펴봐야겠다.
이제 Conv2D 함수는 어떤 변수들을 파라메터로 받는지 확인해보자. [6]의 문서를 확인해보면,
[6] https://keras.io/layers/convolutional/#conv2d
- 첫번째 파라메터는 integer 값으로 몇개의 filter를 쓸 것인가에 해당한다. 하나의 filter로 입력 이미지를 한 번 쭉 훑을 때마다 (convolution 할 때마다) 한 장의 output image가 생성되기 때문에 filter의 개수만큼 출력되는 output image가 생긴다. 이 숫자를 Channel이라고 부른다.
- 두번째 파라메터는 filter의 크기를 결정하는 건데, filter의 차원이 2D이기 때문에 (3, 3) 이런식으로 적기도 하는데 그냥 하나의 값만 적혀있으면 가로 세로 길이가 그 값으로 동일하다는 의미. 여기는 5라고 적혀있으므로 filter의 크기는 5x5가 된다. 그리고 많은 경우 3x3 filter를 쓰는데, 여기서는 strides를 2로(픽셀을 두 칸씩 건너뜀) 할 예정이기 때문에 5x5 filter를 써야 스킵되는 픽셀이 없게 된다.
- strides는 filter를 훑을 때 픽셀을 몇개씩 건너뛰며 convolution 계산을 시킬 건지 결정한다. 1이면 한칸씩 이동하는 거라서 입력과 같은 해상도의 출력이 나오고, 예제 코드에 쓰인 대로 2칸씩 이동하면 가로 세로 길이는 절반이 된다. 이거 때문에 28x28 해상도의 입력 이미지가 14x14 해상도의 출력으로 나오게 된다. 이 이유 때문에 strides를 1로 설정한 CNN 코드에서 처럼 pooling 같은 걸 따로 할 필요가 없던 것이다.
- input_shape은 앞에서 이미 설명했다.
- padding은 filter가 입력 이미지 가장자리 부분에 걸치게 될 때 빈 공간을 어떻게 채울 것인지 설정해주는 것이다. same인 걸 보니 가장자리 값을 그대로 복사해서 채우나보다. 그러고 보니 코너에서는 대각선 빈공간에는 어떤 값으로 채우나 모르겠다. 뭐 크게 중요하지는 않을듯.
- activation은 LeakyReLU를 썼는데 그냥 ReLU는 입력이 음수값일 때 그냥 0으로 만들어버리는데 얘는 입력이 음수값일 때 alpha 값을 곱해주어 아주 0으로 버리지는 않는 함수다. [7]
[7] https://keras.io/layers/advanced-activations/#leakyrelu
- 출력은 14x14x64의 차원을 갖는다. shape은 (None, 14, 14, 64) 형태. None에 해당하는 건 여러 개의 sample data를 한꺼번에 집어넣을 수 있도록 잡아둔 공간인데 (batch라고 부르기도 함), 지금은 모델을 디자인하는 단계이기 때문에 None이라고 표현했다.
self.D.add(Dropout(dropout))
Dropout의 개념은 앞에서 설명했는데, fully connected layer에서의 dropout이 아니라 Conv2D에서의 dropout은 어떻게 적용되는 건지 궁금하다. 그냥 filter들을 하나씩 끄는 건가. 아니면 filter 내에 weight들을 따로 확률적으로 0으로 만들어 주는 건가. 나중에 더 찾아봐야겠다. 일단 기본적으로는 어떤 역할인지는 아니깐 넘어가자.
self.D.add(Conv2D(depth*2, 5, strides=2, padding='same', activation=LeakyReLU(alpha=0.2)))
두번째 2D convolution에 해당하는 코드. depth에 곱해지는 숫자가 두배가 된 것 빼고는 앞에서 다 이미 설명했다. 다만 입력의 shape에서 channel의 수가 64개가 되었기 대문에 filter의 shape은 그냥 (5, 5)가 아니라 (5, 5, 64)가 된다. 여러 channel에 대해 convolution이 어떻게 이루어지는가는 아래 링크의 영상을 보면 이해가 쉽다. 그리고 이 layer의 출력은 7x7x128의 차원을 갖는다. 출력 shape은 (None, 7, 7, 128)
https://youtu.be/KTB_OFoAQcc
self.D.add(Dropout(dropout))
또 한 번 dropout.
self.D.add(Conv2D(depth*4, 5, strides=2, padding='same', activation=LeakyReLU(alpha=0.2)))
세번째 2D convolution. 이번에는 depth에 4가 곱해졌다. 깊다... ㄷㄷ 출력은 4x4x256의 차원을 갖는다. 여기서 잠깐. 7x7이 왜 4x4가 되었는가?! 그것은 3.5x3.5가 될 수 없기 때문이다;; 가로 길이가 7인데, 1부터 시작해서 2칸씩 움직인다면, 1 → 3 → 5 → 7 총 4칸을 거쳐가게 된다. 세로도 마찬가지. 그래서 4x4가 된다. 출력 shape은 (None, 4, 4, 256)
self.D.add(Dropout(dropout))
그리고 또 dropout.
self.D.add(Conv2D(depth*8, 5, strides=1, padding='same', activation=LeakyReLU(alpha=0.2)))
마지막 2D convolution. 여기서는 strides가 1이기 때문에 depth만 깊어지고 출력의 해상도는 입력과 같다. 이로써 이 Conv2D까지 거치게 되면 출력은 4x4x512의 차원이 된다. 출력 shape은 (None, 4, 4, 512)
self.D.add(Dropout(dropout))
마지막으로 dropout 한 번 더.
self.D.add(Flatten())
4x4x512 차원을 8,192 길이의 1차원으로 만들어주는 함수다. 출력 shape은 (None, 8192) 참고로 여기서도 data_format의 default 조건은 channel_last다. 그러니깐 가로줄부터 읽고, 세로줄 순서로 넘어가고, channel 순서로 데이터를 읽어서 1차원으로 나열한다는 것.
self.D.add(Dense(1))
다음으로 우리는 최종 출력이 0에서 1 사이의 값을 갖는 하나의 변수만 가지고 있으면 되기 때문에, 8,192 → 1로 만드는 가장 기본적인 neural network 형태[8]를 만들어 주었다. 출력 shape은 (None, 1)
[8] https://keras.io/layers/core/#dense
self.D.add(Activation('sigmoid'))
끝이 보인다!. 마지막으로 activation 함수를 넣어준다. sigmoid 함수는 실수값을 갖는 모든 입력 값을 0에서 1 사이 값으로 만들어 준다. [9] Activation layer의 출력 shape은 입력의 shape과 같다. 그래서 (None, 1)
[9] https://en.wikipedia.org/wiki/Sigmoid_function
self.D.summary()
summary() 함수는 D라는 model이 어떻게 디자인되어있는지를 출력해서 보여준다. 꼭 필요한 코드는 아니지만 내가 디자인 한 구조가 잘 반영되었는지 확인해볼 수 있기 때문에 유용한 코드다.
그래서 우리는 위와 같은 Discriminator를 만드는 코드를 살펴보았다! 파라메터 하나하나 분석하는 건 조금 귀찮은 일이었지만, 막상 다 살펴보고 나니 자신감이 생기는 것 같은 느낌적 느낌이다?!
지금부터 설명하는 코드는 Generator model을 만들어 주는 함수의 코드다.

이제는 이미지를 생성하는 generator에 대해 살펴보자! 입력단이 100차원의 노이즈인데, 각 element들은 -1에서 1 사이의 고르게 퍼져있는 랜덤값들이라고 한다. 진짜 노이즈다. 다만 -1부터 1 범위의 100차원 공간 상에 고루 퍼진 노이즈라서, 해당 100차원 공간상의 어떤 곳이든 출력되는 이미지가 손글씨처럼 나오도록 학습시키는 입력이라고 생각하면 되겠다. 근데, 100차원인 이유는 무엇일까... 뇌피셜에 의하면 VAE에서 손글씨를 학습할 때 latent space가 100차원 정도면 잘 학습이 되었나보지... ㅎㅎ
그 다음 convolution의 반대 역할을 하는 구조가 보인다. 이미지의 해상도는 점점 올라가고, 깊이(채널?)는 점점 작아진다. discriptor를 뒤집어 놓은듯한 구조이면서도 차이점이 있다. 왜 그런지는 역시 논문을 보거나... 노하우(?)가 생겨야 알 수 있겠지. 그리고 원문에 보면 원래 DCGAN은 fractionally-strided convolution을 사용하는 것으로 제안되었는데, upsampling이라는 기법을 사용했다고 한다. 그러면 더 그럴듯한 손글씨가 나온다나... 이유야 뭐 지금 수준에서 알긴 어렵다.
자 이제 코드로 들어가보자. 앞서 대충 코드를 익혀두었으니 이제는 조금 더 수월하게 보드를 이해할 수 있으리라!
self.G = Sequential()
Sequential 방법으로 generator의 모델을 만들기로 한다.
dropout = 0.4
여기서도 dropout은 0.4다.
depth = 64+64+64+64
으잉? depth가 64가 아닌 64가 4개 더해진 256? 아 뒤에 코드를 보니 깊이가 하나씩 바뀔 때마다 나누기를 하네...
dim = 7
아마 이미지 정보를 만들 때 시작하는 해상도가 7x7인가보다.
self.G.add(Dense(dim*dim*depth, input_dim=100))
입력 100 → 출력 12,544(=7x7x256)이 되는 가장 기본적인 fully connected neural network을 만든다.
self.G.add(BatchNormalization(momentum=0.9))
함수 이름부터 무섭게 생긴 녀석이 나타났다... 일단 관련 문서[10]를 찾아보자. 근데 뭐 개념을 이해하는데는 큰 도움이 안된다.
[10] https://keras.io/layers/normalization/
사실 batch normalization은 딥러닝을 공부한 사람이면 한 번 쯤 들어봤을 법도 한데, 실제 개념은 이 글 쓰면서 다시 공부했다. -ㅁ- 기본적인 개념은 [11]에서 이해할 수 있고, 좀 더 구체적인 수식설명까지 보려면 [12]를 보면 된다. 혹시 한국어로 듣고 싶다면 [13] 여기로! 개인적으로는 [11]과 [12]를 본 후에 [13]을 보기를 권장한다.
[11] https://youtu.be/nUUqwaxLnWs
[12] https://youtu.be/5qefnAek8OA
[13] https://youtu.be/TDx8iZHwFtM
그러나! 저 링크를 다 들어가서 보고 싶지 않을테니 (ㅋㅋ;) 요약을 하자면 (근데 각 영상이 15분 미만만 보면 되기 때문에 그리 부담이 되는 것은 아니다.), 입력 데이터의 분포가 학습시에 계속 바뀌면서 들어오게 되면, 중간 layer들에서는 값들이 생각 이상으로 많이 출렁이게 되기 때문에(internal covariate shift라고 부름), 샘플 묶음(batch)마다의 평균과 분산을 계산해서 업데이트하고 이를 이용해 데이터를 정규화시켜서 사용하겠다는 개념이다. 그러면 각 layer마다 출력되는 값들의 분포가 안정적으로 유지되기 때문에 학습시에 효율이 올라간다고 한다. 모평균(population mean)과 모분산(population vaiance)으로 정규화 시키지 않는 이유는 학습할 때 모든 데이터를 다 가져다가 계산해서 쓰기에는 시간이 너무 오래걸리기 때문일 것이다. 어쨌든 이 방법을 쓰면 weights 값들의 초기화가 그다지 필요 없고, 학습 속도에도 도움이 되며, overfitting도 어느정도 막아준다고 한다(이거는 batch를 사용하기 때문인 것도 있을듯).
자 이제 그러면 다시 코드로 돌아와서, momentum 저 녀석은 뭔지 살펴보자. 이건 찾아보니, 현재 batch에서 계산된 평균과 분산을 기존까지 계산해온 평균과 분산에 어떻게 업데이트 시키느냐를 의미하는 것이다. 평균을 예로 들면, (새평균) = (기존평균)*0.9 + (현재 batch의 평균)*(1-0.9) 이렇게 하겠다는 의미. 코드 상에서 0.9로 설정되어 있어서 예시 수식에도 0.9를 썼다.
self.G.add(Activation('relu'))
Activation 함수로는 ReLU를 쓴다.
self.G.add(Reshape((dim, dim, depth)))
앞서 출력은 12,544(=7x7x256) 길이의 1차원이었기 때문에, 이를 (7, 7, 256) shape으로 바꾸어준다. 더 정확하게는 batch를 고려해서 (None, 7, 7, 256)이다.
self.G.add(Dropout(dropout))
앞서 batch normalization을 하면 overfitting을 줄일 수 있다고 하던데... 여기에서 dropout을 또 추가한 건.... 아마도 개발자 마음이겠지...?
self.G.add(UpSampling2D())
UpSampling2D 함수는, 2차원 데이터를 두번씩 반복해서 해상도를 두 배 늘리는 함수다. 가로와 세로에 따라서 반복하는 횟수를 지정할 수도 있는데 기본 값은 두 배 씩 늘리는 것이다. data_format의 기본값은 channel_last. 결론적으로 이 함수를 통해 얻어지는 출력은 (None, 14, 14, 256)이 된다.
self.G.add(Conv2DTranspose(int(depth/2), 5, padding='same'))
Conv2DTranspose는 직관적으로는 convolution이 하는 역할의 반대라고 생각하면 된다. 근데 실제 계산 과정은 뭔가 조금 다르다. 정상적인 방향의 convolution에서 filter가 한 번 계산될 때, 여러개 input 데이터가 filter와 곱해져서 하나의 output 데이터를 만든다. 반면 이를 역으로 생각한다면, 하나의 데이터로 여러 개의 데이터를 만들어야 하고, 그에 해당하는 여러 개의 데이터는 또 다른 데이터로부터 구해지는 것들과 병합돼야 한다. 이게 말로 설명하기 너무 어려운데, 기본 convolution은 many to one 계산의 반복이었다면, deconvolution은 many to many의 계산이 이루어져야 한다. 개념을 돕기 위해 영상[14]을 하나 첨부한다. 사실 근데 영상을 봐도 나는 잘 이해를 못했다. ㅋㅋ; zero padding 후에 일반 convolution 하듯이 deconvolution 하는 영상[15]도 있어서 가져와 본다. 다만 다중 channel일 때는 일반 convolution에서의 다중 channel을 다루는 것과는 다를 것이다.
[14] https://youtu.be/8DiqJj5tPlA
[15] https://youtu.be/uOKvea5pATM
입력 파라미터는 출력될 channel의 수, filter의 크기, padding의 종류가 표시되어 있다. 개념적으로 정의되어 사용되는 것들은 Conv2D와 크게 다른 건 없다. (deconvolution 알고리즘은 위에서 말했듯이 좀 다르겠지만) 그리고 한가지 더 봐야할 점은 strider를 따로 지정하지 않았는데 default 값이 1이다. 그래서 입력과 출력의 dimension이 같게 된다. 앞서 UpSampling2D로 차원을 뿔려놨으니, 여기서 출력도 뿔려진 상태로 유지가 된다. 다만 channel은 절반이 된다. 출력의 shape은 (None, 14, 14, 128)이다.
self.G.add(BatchNormalization(momentum=0.9))
여기서도 batch normalization을 붙여 준다. 아무래도 차원을 뻥튀기 하는 구조다보니 batch normalization이 유용하게 사용되나보다.
self.G.add(Activation('relu'))self.G.add(UpSampling2D())
함수 설명은 중복이므로 최종 출력의 shape만 언급하고 넘어가겠다.
(None, 14, 14, 128) → (None, 28, 28, 128)
self.G.add(Conv2DTranspose(int(depth/4), 5, padding='same'))
(None, 28, 28, 128) → (None, 28, 28, 64)
self.G.add(BatchNormalization(momentum=0.9))
self.G.add(Activation('relu'))self.G.add(Conv2DTranspose(int(depth/8), 5, padding='same'))
(None, 28, 28, 64) → (None, 28, 28, 32)
self.G.add(BatchNormalization(momentum=0.9))
self.G.add(Activation('relu'))
self.G.add(Conv2DTranspose(1, 5, padding='same'))
드디어 마지막 단계까지 왔다. 이 과정을 거치면 28x28x1의 데이터가 얻어진다. 한 장의 이미지가 생성된 것이다. 다만 아직 데이터 값의 범위가 실수 값의 범위이다.
(None, 28, 28, 32) → (None, 28, 28, 1)
self.G.add(Activation('sigmoid'))
sigmoid 함수를 이용해서, 이제 각 픽셀값이 0에서 1의 값을 갖는 28x28의 이미지가 나왔다.
이제 discriminator와 generator의 modeling을 위한 함수 정의가 완료되었다. 이제는 각 모델을 불러와서 optimer와 loss function등을 정의하여 compile하고, 학습시키는 일이 남았다.
optimizer = RMSprop(lr=0.0008, clipvalue=1.0, decay=6e-8)
코드만 보고 1차원적으로 생각했을 때는, optimizer를 RMSprop이라는 녀석으로 설정하는 코드다. 사실 좀 고민이 된다. optimizer의 깊은(?) 의미까지 다 들여다보아야 할까. 사실 어느 정도는 이해를 하고 있어야 내가 풀고자 하는 문제에서 어떤 optimizer가 적절한지를 선택할 수는 있을텐데... 일단, 간단하게라도 알아보고 가자. Optimizer는 우리가 모델링한 network의 weights 들이 어떤 값이 되어야만, 가장 최적화된 성능을 가지는지를 찾아주는 방법론이다. 가장 많이 들어봤을 방법으로는 gradient descent optimization[16]이 있다. 현재 weights 들을 조금씩 바뀌게 해서 어떻게 weights가 바뀔 때 목적한 성능에 더 가까워지느냐(혹은 loss function이 작아지느냐)를 미분 계산을 통해 찾아가는 방법으로, 몇몇 가정(assumption)들이 필요하기는 하지만, 어지간히 잘 동작하는 방법이다. 여기에도 몇몇 트릭들을 더 추가해서 여러 방법들이 존재할텐데, 사실 내가 그 정도까지 다 알고있지는 못하고, 예제 코드를 따라가는 수준에서 다 알 수는 없을 것 같다. 그래도 궁금하다면 [17]을 참고하면 좋을듯. (사실 나도 안 읽어봤다. 검색하다 찾은 글인데 그림이 직관적으로 잘 그려져 있기에... ㅎㅎ) 내가 다른 예제 코드에서 본 방법 중에는 Adam이라는 방법이 많이 보였었다. Keras에서 사용할 수 있는 다른 여러 optimizer들은 [18]에서 확인해볼 수 있다.
[16] http://ruder.io/optimizing-gradient-descent/
[17] http://ruder.io/deep-learning-optimization-2017/
[18] https://keras.io/optimizers/#usage-of-optimizers
다시 코드로 돌아와서, 본 예제에서는 RMSprop이라는 함수로 realistic한 이미지를 만들어내는 데에는 좋은 성능을 갖기 때문에 채용했다고 본문에서는 밝히고 있다. 참고로 RNN학습에도 좋은 성능을 보인다고 한다. 방법론은 [19]에서 발표자료로 설명해두었으니 참고해보자. 함수 파라미터로 lr은 learning rate에 해당하는 값으로 0.0008이라는 꽤나 작은 값을 사용했는데, 이 값은 아마도 이 예제 코드를 만든 사람들이 휴리스틱하게 찾은 값일테다. learning rate가 너무 크면 optimizer가 최적의 값을 찾지 못하고 이리 저리 방황하는 성능을 보이게 될테고, 너무 작으면 학습이 전혀 느리게 되는 단점이 있다. 우리가 앞서 디자인한 discriminator의 구조는 꽤나 복잡하기 때문에 이정도 작은 값은 써야 optimizer가 괜찮은 성능을 내는가보다. clipvalue는 gradients들의 절대 값이 여기서 설정한 값들보다 클 때 잘리도록(clipped) 하는 값이라고 한다. 그런데! 이게 Keras가 최신버젼으로 업데이트 되면서부터 이 값은 입력 파라미터 값이 더이상 아니다. ㅎㅎ 그래서 그냥 넘어가도록 하자. 실제 예제 코드에서도 clipvalue가 빠진 채로 함수가 불러지고있다. decay 값은 학습이 진행되면서 learning rate를 줄여나가는 비율이다. 앞서 learning rate가 클 수록 optimizer가 방황한다고 표현을 해놨는데, learning rate가 작다고 하더라도 마지막 정말 정확한 최적값을 찾고자 한다면 learning rate가 학습이 진행될 때마다 더 작아지게 하는 것도 방법 중 하나다.
[19] http://www.cs.toronto.edu/~tijmen/csc321/slides/lecture_slides_lec6.pdf
위에서 실컷 설명 파라미터를 설명했는데, 최신 버젼 소스코드를 보면 파라미터 값이 좀 다르게 아래와 같이 구현되어 있다.
optimizer = RMSprop(lr=0.0001, decay=3e-8)
self.DM = Sequential()
self.DM.add(self.discriminator())
이제 DCGAN 클래스에 DM이라는 이름의 discriminator model을 앞서 설명한 discriminator 함수로 만들어 줬다. 근데 D를 그냥 써도 되는데 왜 또 DM이라는 모델을 또 정의해서 거기에 D를 집어 넣어서 쓰는 걸까. 그건 discriminator만 학습 시킬 때와 generator와 함께 붙어서 학습될 때 각각 다른 compilation을 필요로 하기 때문일 것이다. 그래서 DM을 따로 정의해 compile을 하고, 뒤에서 보면 AM을 따로 정의해서 또 다른 compile을 넣어 놓는다.
self.DM.compile(loss='binary_crossentropy', optimizer=optimizer, metrics=['accuracy'])
이제 discriminator model을 어떻게 학습시킬지 설정해주자. loss는 loss function을 무엇을 쓸 지를 설정해주는 것으로 여기서는 cross entropy를 사용했다. discriminator model은 목표값과 유사한 값을 출력하도록 학습시키는 것이 아니고, 맞냐/아니냐(0 또는 1)의 값을 확실하게 이야기해주도록 학습시키기 때문에 cross entropy를 쓰는 것이 유리하다. cross entropy와 mse의 차이점이 궁금하다면, 아래 영상[20]의 29분 30초경부터의 설명을 보면 좋다. optimizer는 앞서 설명한 RMSprop를 사용하고, metrics은 학습시 한 epoch이 끝날 때마다 training set과 validation set(주어진 경우)에 대해 그 결과를 확인해볼 수 있게 어떤 걸 기록할지 알려주는 것이다. 여기서는 정확도를 확인해볼 수 있는 가장 기본적인 'accuracy'를 썼다. metrics 설정은 학습에 영향을 주는 것은 아니고 성능을 평가하기 위한 것으로만 사용된다. 참고 설명 [21]
[20] https://youtu.be/o_peo6U7IRM?t=29m35s
[21] https://machinelearningmastery.com/custom-metrics-deep-learning-keras-python/
이제 generator와 discriminator가 어떻게 아래 그림과 같이 엮여서 동작하게 할지를 구현해보자.

Generator와 discriminator도 회상해볼 겸 다시 살펴보자.
기본적으로 generator에서 생성되는 모든 이미지는 noise로부터 생긴 이미지이 때문에 가짜 이미지다. discriminator는 가짜인지를 밝혀내는 역할을 하니, 이 adversarial model에 있는 discriminator가 가짜이미지를 걸러내지 못할 수록 generator가 이미지를 잘 만들고 있다는 이야기가 된다.
위 구조는 아래와 같은 코드로 구성되고, discriminator model을 만들 때와 learning rate과 decay 값이 좀 다를 뿐 구현 과정은 동일하다.
optimizer = RMSprop(lr=0.0004, clipvalue=1.0, decay=3e-8)
self.AM = Sequential()
self.AM.add(self.generator())
self.AM.add(self.discriminator())
self.AM.compile(loss='binary_crossentropy', optimizer=optimizer, metrics=['accuracy'])
아 참고로 여기서도 최신 코드에는 RMSprop를 위 예제가 아니라 아래와 같이 쓰고 있다. Adverarial model은 DCGAN 클래스에서 AM이라는 이름을 갖는다.
optimizer = RMSprop(lr=0.0001, decay=3e-8)
근데 난 여기서 한가지 궁금한 점이 생겼다. DM에도 discriminator가 학습되고 있고, AM에서도 disriminator가 들어가있는데, 그러면 한 discriminator에 optimizer가 두번 쓰이는 거고, 학습시에 충돌이 생기지 않을까?
역시나, 원글에서 그 다음 내용을 읽으니 추가 설명이 있었다.

학습 부분이 가장 어려운 파트라고 한다. 일단 discriminator model(DM)이 진짜 이미지와 가짜 이미지를 구별할 수 있도록 먼저 학습시킨다. 위 이미지에서 generator에서 나오는 이미지에 label을 0이라고(가짜 이미지라고) 알려준 상태로 학습을 시키는 것이다. 그러니깐 아직은 generator를 학습시키는 게 아니고 discriminator만 학습시키는 거다. 그리고 나중에 DM과 AM을 번갈아가면서 학습을 시킨다고 한다. 그니깐 DM과 AM이 동시에 학습되는 게 아니었다.
학습을 어떤 식으로 시키는지 코드를 보자.
images_train = self.x_train[np.random.randint(0,
self.x_train.shape[0], size=batch_size), :, :, :]
코드가 조금 복잡하다. 조금 들여다보면, x_train은 DCGAN 클래스에서 이미 MNIST 데이터를 불러온 애들이다. 데이터를 불러오는 코드를 보자.
from tensorflow.examples.tutorials.mnist import input_data
(중략)
self.x_train = input_data.read_data_sets("mnist", one_hot=True).train.images
self.x_train = self.x_train.reshape(-1, self.img_rows, self.img_cols, 1).astype(np.float32)
x_train은 텐서플로우에서 기본으로 제공하는 MINIST 데이터에서 training 이미지에 해당하는 데이터를 불러와서 (-1, 이미지의 세로크기, 이미지의 가로크기, 채널수)의 형태로 reshape된 녀석들이다. -1은 전체 데이터 갯수에 맞춰서 이미지의 세로크기, 가로크기, 채널 수가 결정되면 자동으로 유추될 수 있는 총 이미지의 갯수라고 생각하면 된다. 예를 들어 1,000 길이의 data가 있었고, 이미지의 크기가 10x10이라면, (-1, 10, 10, 1)로 reshape하면 -1에 해당하는 값은 10이라고 생각하면 되고, 이는 총 이미지의 개수와 같다. 이걸 일반화 시키기 위해 -1이라고 한 것.
그리고 이 x_train 데이터의 순서를 섞기 위해 numpy의 함수인 random.randint()를 썼다. random.randint() 함수는 중복된 index도 만들어낸다는 점이 있어서 한 데이터가 여러번 학습에 사용될 수도 있다. 여튼 randint() 함수의 첫 파라미터는 생성할 숫자의 최소값, 그 다음 파라미터는 최대값(이지만 포함하지 않는), 생성할 갯수(size)의 의미를 갖는다. 그러므로 현재 x_train에 들어있는 데이터 중에서 batch_size 갯수만큼을 임의로 뽑아서 하나의 images_train batch를 만들겠다는 의미다.
사실 이 코드는 keras도 아니고 numpy와 기본 python array 관련 코드인데 괜히 설명이 길어졌다;; 그래도 쌩초보인 나로서는 일일이 다 공부해서 확인해보는 수밖에...
noise = np.random.uniform(-1.0, 1.0, size=[batch_size, 100])
이제 노이즈를 만들 차례. -1부터 1 사이에 고르게 분포된 100차원의 랜덤 값을 batch_size 갯수만큼 만드는 코드다. noise 변수의 shape은 (batch_size, 100)이다.
images_fake = self.generator.predict(noise)
우선 generator에 noise를 넣어서 만들어진 이미지는 생성된 가짜 이미지이므로 images_fake라고 이름을 지정해 놓는다.
x = np.concatenate((images_train, images_fake))
concatenate는 말 그대로 두 데이터를 잇는다는 내용이다. 위 코드를 통해 x에는 MNIST 데이터로부터 읽어온 진짜 손글씨 이미지와, generator로부터 만들어진 가짜 손글씨 이미지가 모두 포함되게 된다.
y = np.ones([2*batch_size, 1])
y[batch_size:, :] = 0
label로 사용될 y의 전반부에는 진짜 이미지 갯수만큼 0으로, 후반부는 (즉, 가짜 이미지 갯수만큼은) 1로 설정해놓는다. 우리는 앞서 코드에서 진자 이미지 갯수와 가짜 이미지 갯수가 모두 batch_size였으므로 y의 길이는 총 2*batch_size가 된다. 위 코드는 일단 2*batch_size 길이 만큼 1로 가득찬 y를 만들고, 전반부 batch-size 갯수만큼을 0으로 다시 덮어 씌운 코드다. 두번째 줄에서 batch_size 뒤에 :이 더 붙은 것은 처음 인덱스부터 batch_size갯수만큼의 모든 element를 가리키는 의미다. :가 없으면 batch_size 번째의 element만 0이 되어 의도와 다르게 된다.
d_loss = self.discriminator.train_on_batch(x, y)
이제 우리가 만든 x와 y로 discriminator를 학습시키고, 출력 loss 값을 d_loss로 받아오는 코드다. 보통 하나의 모델을 여러번의 epoch을 통해 학습시키는 게 일반적이었지만, 여기서는 한 번에 한 batch 만을 통과 시켜서 학습시키는 모양이다.
y = np.ones([batch_size, 1])
noise = np.random.uniform(-1.0, 1.0, size=[batch_size, 100])
이번에는 AM을 학습시키기 위한 입력과 출력을 만든다. 입력은 모두 noise고, 따라서 y는 모두 가짜라고 이야기하도록 1로 세팅한다.
a_loss = self.adversarial.train_on_batch(noise, y)
그리고 AM을 noise와 y로 한 번 업데이트 시킨다. 출력 loss 값은 a_loss 로받아온다.
이렇게 구현된 training 과정(discriminator model과 adversarial model을 번갈아 가며 학습시키는 과정)을 계속 반복한다. 원글에 의하면 1000번 이상 반복하면 꽤 괜찮은 결과가 나온다고 한다.
코드 분석 끝!